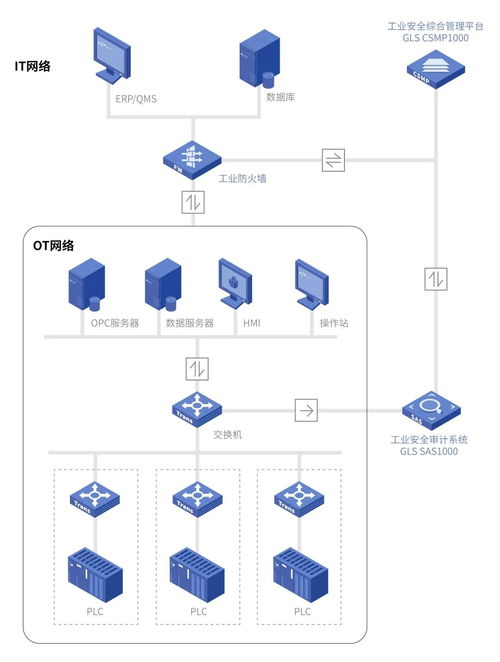
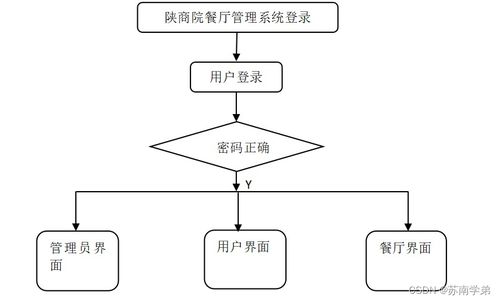
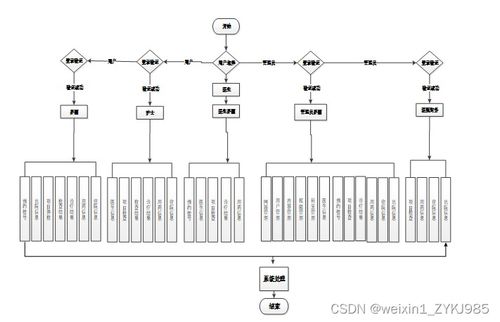
2021年,計(jì)算機(jī)專業(yè)作為信息技術(shù)領(lǐng)域的核心學(xué)科,展現(xiàn)出蓬勃的發(fā)展態(tài)勢。其中,計(jì)算機(jī)系統(tǒng)服務(wù)是專業(yè)的重要組成部分,它涵蓋了計(jì)算機(jī)系統(tǒng)的設(shè)計(jì)、開發(fā)、維護(hù)和優(yōu)化等關(guān)鍵環(huán)節(jié)。本篇文章將詳細(xì)介紹計(jì)算機(jī)專業(yè)在2021年的發(fā)展?fàn)顩r,并重點(diǎn)聚焦于計(jì)算機(jī)系統(tǒng)服務(wù)領(lǐng)域,幫助讀者全面了解該專業(yè)的核心內(nèi)容與職業(yè)前景。
一、計(jì)算機(jī)專業(yè)概述
計(jì)算機(jī)專業(yè)在2021年繼續(xù)保持高速增長,受益于數(shù)字經(jīng)濟(jì)的興起和人工智能、大數(shù)據(jù)、云計(jì)算等技術(shù)的普及。該專業(yè)旨在培養(yǎng)學(xué)生掌握計(jì)算機(jī)科學(xué)的基礎(chǔ)理論、編程技能以及系統(tǒng)設(shè)計(jì)能力。課程設(shè)置通常包括數(shù)據(jù)結(jié)構(gòu)、算法、操作系統(tǒng)、網(wǎng)絡(luò)技術(shù)、數(shù)據(jù)庫系統(tǒng)等核心模塊,同時(shí)強(qiáng)調(diào)實(shí)踐與創(chuàng)新。2021年,眾多高校進(jìn)一步優(yōu)化了課程體系,加入了前沿技術(shù)如機(jī)器學(xué)習(xí)、物聯(lián)網(wǎng)和區(qū)塊鏈等,以適應(yīng)行業(yè)需求。畢業(yè)生就業(yè)范圍廣泛,涵蓋軟件開發(fā)、數(shù)據(jù)分析、網(wǎng)絡(luò)安全和系統(tǒng)架構(gòu)等多個(gè)方向。
二、計(jì)算機(jī)系統(tǒng)服務(wù)詳解
計(jì)算機(jī)系統(tǒng)服務(wù)是計(jì)算機(jī)專業(yè)中的一個(gè)關(guān)鍵分支,它專注于計(jì)算機(jī)系統(tǒng)的整體運(yùn)行、維護(hù)和服務(wù)支持。在2021年,隨著企業(yè)數(shù)字化轉(zhuǎn)型加速,計(jì)算機(jī)系統(tǒng)服務(wù)的重要性日益凸顯。其主要內(nèi)容包括:
- 系統(tǒng)設(shè)計(jì)與開發(fā):涉及硬件與軟件的集成設(shè)計(jì),確保系統(tǒng)高效穩(wěn)定。例如,在云計(jì)算環(huán)境中,系統(tǒng)服務(wù)需要優(yōu)化資源分配和負(fù)載均衡。
- 系統(tǒng)維護(hù)與管理:包括日常監(jiān)控、故障排除和性能調(diào)優(yōu),保障系統(tǒng)24/7可靠運(yùn)行。2021年,自動化運(yùn)維工具如Ansible和Kubernetes的應(yīng)用更加普及。
- 安全服務(wù):隨著網(wǎng)絡(luò)威脅增多,系統(tǒng)服務(wù)強(qiáng)調(diào)數(shù)據(jù)保護(hù)和訪問控制,采用加密技術(shù)和入侵檢測系統(tǒng)來防御攻擊。
- 用戶支持與培訓(xùn):提供技術(shù)咨詢和用戶培訓(xùn),幫助企業(yè)和個(gè)人高效使用計(jì)算機(jī)系統(tǒng)。
在2021年,計(jì)算機(jī)系統(tǒng)服務(wù)領(lǐng)域的發(fā)展趨勢包括向云端遷移、采用AI驅(qū)動的自動化管理,以及綠色計(jì)算以降低能耗。職業(yè)機(jī)會涵蓋系統(tǒng)管理員、網(wǎng)絡(luò)工程師、技術(shù)支持專員和云服務(wù)專家等崗位,薪資水平普遍較高。
三、2021年計(jì)算機(jī)專業(yè)與系統(tǒng)服務(wù)的結(jié)合
2021年,計(jì)算機(jī)專業(yè)教育更加注重理論與實(shí)踐的結(jié)合,特別是在計(jì)算機(jī)系統(tǒng)服務(wù)方面。高校通過項(xiàng)目式學(xué)習(xí)和校企合作,讓學(xué)生參與真實(shí)系統(tǒng)部署和維護(hù)任務(wù),培養(yǎng)解決實(shí)際問題的能力。例如,學(xué)生可能參與構(gòu)建企業(yè)級服務(wù)器集群或優(yōu)化移動應(yīng)用的后端系統(tǒng)。這種教育模式不僅提升了學(xué)生的技能,還為他們就業(yè)打下堅(jiān)實(shí)基礎(chǔ)。
四、未來展望
計(jì)算機(jī)系統(tǒng)服務(wù)將繼續(xù)演進(jìn),與邊緣計(jì)算、5G和量子計(jì)算等新技術(shù)融合。對于學(xué)生和從業(yè)者而言,持續(xù)學(xué)習(xí)新技術(shù)、注重跨學(xué)科知識將是關(guān)鍵。2021年的計(jì)算機(jī)專業(yè)介紹顯示,掌握計(jì)算機(jī)系統(tǒng)服務(wù)能力將幫助個(gè)人在競爭激烈的就業(yè)市場中脫穎而出。
2021年的計(jì)算機(jī)專業(yè)以計(jì)算機(jī)系統(tǒng)服務(wù)為核心亮點(diǎn),體現(xiàn)了技術(shù)的前沿性和應(yīng)用的廣泛性。無論是學(xué)術(shù)研究還是職業(yè)發(fā)展,這一領(lǐng)域都提供了豐富的機(jī)遇和挑戰(zhàn)。